boolcmp(athlete a, athlete b){ return a.dist < b.dist; }
intmain(){ int n = 0, id = 0, x = 0, y = 0; scanf("%d", &n); athlete athletes[10010]; for (int i = 0; i < n; i++) { scanf("%d %d %d", &id, &x, &y); athletes[i] = athlete(id, x * x + y * y); } std::sort(athletes, athletes + n, cmp); printf("%04d %04d", athletes[0].id, athletes[n - 1].id); return0; }
The task of this problem is simple: insert a sequence of distinct positive integers into a hash table first. Then try to find another sequence of integer keys from the table and output the average search time (the number of comparisons made to find whether or not the key is in the table). The hash function is defined to be H(key)=key%TSize where TSize is the maximum size of the hash table. Quadratic probing (with positive increments only) is used to solve the collisions. Note that the table size is better to be prime. If the maximum size given by the user is not prime, you must re-define the table size to be the smallest prime number which is larger than the size given by the user.
Input Specification:
Each input file contains one test case. For each case, the first line contains 3 positive numbers: MSize, N, and M, which are the user-defined table size, the number of input numbers, and the number of keys to be found, respectively. All the three numbers are no more than 104. Then N distinct positive integers are given in the next line, followed by M positive integer keys in the next line. All the numbers in a line are separated by a space and are no more than 105.
Output Specification:
For each test case, in case it is impossible to insert some number, print in a line X cannot be inserted. where X is the input number. Finally print in a line the average search time for all the M keys, accurate up to 1 decimal place.
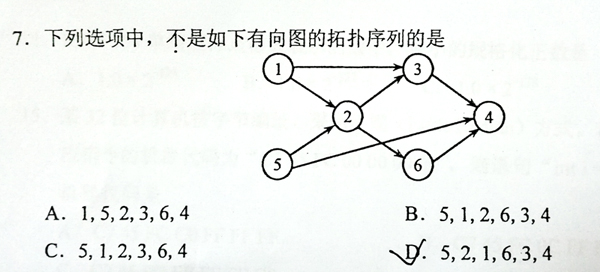
This is a problem given in the Graduate Entrance Exam in 2018: Which of the following is NOT a topological order obtained from the given directed graph? Now you are supposed to write a program to test each of the options.
Input Specification:
Each input file contains one test case. For each case, the first line gives two positive integers N (≤ 1,000), the number of vertices in the graph, and M (≤ 10,000), the number of directed edges. Then M lines follow, each gives the start and the end vertices of an edge. The vertices are numbered from 1 to N. After the graph, there is another positive integer K (≤ 100). Then K lines of query follow, each gives a permutation of all the vertices. All the numbers in a line are separated by a space.
Output Specification:
Print in a line all the indices of queries which correspond to “NOT a topological order”. The indices start from zero. All the numbers are separated by a space, and there must no extra space at the beginning or the end of the line. It is graranteed that there is at least one answer.
In computer science, a heap is a specialized tree-based data structure that satisfies the heap property: if P is a parent node of C, then the key (the value) of P is either greater than or equal to (in a max heap) or less than or equal to (in a min heap) the key of C. A common implementation of a heap is the binary heap, in which the tree is a complete binary tree. (Quoted from Wikipedia at https://en.wikipedia.org/wiki/Heap_(data_structure) ) Your job is to tell if a given complete binary tree is a heap.
Input Specification:
Each input file contains one test case. For each case, the first line gives two positive integers: M (≤ 100), the number of trees to be tested; and N (1 < N ≤ 1,000), the number of keys in each tree, respectively. Then M lines follow, each contains N distinct integer keys (all in the range of int), which gives the level order traversal sequence of a complete binary tree.
Output Specification:
For each given tree, print in a line Max Heap if it is a max heap, or Min Heap for a min heap, or Not Heap if it is not a heap at all. Then in the next line print the tree’s postorder traversal sequence. All the numbers are separated by a space, and there must no extra space at the beginning or the end of the line.
// post order traversal sequence voidprint_post_order(int *arr, int n, int cur){ if (cur > n) return; int left_child = 2 * cur, right_child = 2 * cur + 1; print_post_order(arr, n, left_child); print_post_order(arr, n, right_child); if (cur != 1) printf("%d ", arr[cur]); }
boolmin_heap(int *arr, int n, int cur){ if (cur >= n) returntrue; int left_child = cur * 2, right_child = cur * 2 + 1; if (right_child <= n) { if (arr[left_child] >= arr[cur] && arr[right_child] >= arr[cur]) { returnmin_heap(arr, n, left_child) && min_heap(arr, n, right_child); } } elseif (left_child <= n) { if (arr[left_child] >= arr[cur]) { returnmin_heap(arr, n, left_child) && min_heap(arr, n, right_child); } } else { returntrue; } returnfalse; }
boolmax_heap(int *arr, int n, int cur){ if (cur >= n) returntrue; int left_child = cur * 2, right_child = cur * 2 + 1; if (right_child <= n) { if (arr[left_child] <= arr[cur] && arr[right_child] <= arr[cur]) { returnmax_heap(arr, n, left_child) && max_heap(arr, n, right_child); } } elseif (left_child <= n) { if (arr[left_child] <= arr[cur]) { returnmax_heap(arr, n, left_child) && max_heap(arr, n, right_child); } } else { returntrue; } returnfalse; }
intmain(){ int m = 0, n = 0; scanf("%d %d", &m, &n); for (int i = 0; i < m; i++) { int *arr = newint[1030]; for (int j = 1; j <= n; j++) { scanf("%d", &arr[j]); } if (max_heap(arr, n, 1)) { printf("Max Heap\n"); } elseif (min_heap(arr, n, 1)) { printf("Min Heap\n"); } else { printf("Not Heap\n"); } print_post_order(arr, n, 1); printf("%d\n", arr[1]); delete[] arr; } return0; }
Given a collection of number segments, you are supposed to recover the smallest number from them. For example, given {32, 321, 3214, 0229, 87}, we can recover many numbers such like 32-321-3214-0229-87 or 0229-32-87-321-3214 with respect to different orders of combinations of these segments, and the smallest number is 0229-321-3214-32-87.
Input Specification:
Each input file contains one test case. Each case gives a positive integer N (<=10000) followed by N number segments. Each segment contains a non-negative integer of no more than 8 digits. All the numbers in a line are separated by a space.
Output Specification:
For each test case, print the smallest number in one line. Do not output leading zeros.
One way that the police finds the head of a gang is to check people’s phone calls. If there is a phone call between A and B, we say that A and B is related. The weight of a relation is defined to be the total time length of all the phone calls made between the two persons. A “Gang” is a cluster of more than 2 persons who are related to each other with total relation weight being greater than a given threshold K. In each gang, the one with maximum total weight is the head. Now given a list of phone calls, you are supposed to find the gangs and the heads.
Input Specification:
Each input file contains one test case. For each case, the first line contains two positive numbers N and K (both less than or equal to 1000), the number of phone calls and the weight threthold, respectively. Then N lines follow, each in the following format: Name1 Name2 Time where Name1 and Name2 are the names of people at the two ends of the call, and Time is the length of the call. A name is a string of three capital letters chosen from A-Z. A time length is a positive integer which is no more than 1000 minutes.
Output Specification:
For each test case, first print in a line the total number of gangs. Then for each gang, print in a line the name of the head and the total number of the members. It is guaranteed that the head is unique for each gang. The output must be sorted according to the alphabetical order of the names of the heads.
vector<vector<int> > net(len); int times[len], isVisited[len];
structGang { int index, cnt;
Gang(int m_index, int m_cnt) { index = m_index; cnt = m_cnt; } };
boolcmp(struct Gang a, struct Gang b){ return a.index < b.index; }
intgetIndex(char *name){ int index = 0; for (int i = 0; i < 3; i++) { index = index * 26 + name[i] - 'A'; } return index; }
voidprintName(int index){ printf("%c", index / (26 * 26) + 'A'); printf("%c", index % (26 * 26) / 26 + 'A'); printf("%c", index % 26 + 'A'); }
voiddfs(int &cnt, int cur, int &head, int &total){ for (auto it = net[cur].begin(); it != net[cur].end(); it++) { if (!isVisited[*it]) { isVisited[*it] = 1; if (times[head] < times[*it]) head = *it; cnt++; total += times[*it]; dfs(cnt, *it, head, total); } } }
intmain(){ int n = 0, k = 0; scanf("%d %d", &n, &k); for (int i = 0; i < n; i++) { char name1[4], name2[4]; int time = 0; scanf("%s %s %d", name1, name2, &time); int index1 = getIndex(name1), index2 = getIndex(name2); net[index1].push_back(index2); net[index2].push_back(index1); times[index1] += time; times[index2] += time; } vector<struct Gang> ans; for (int i = 0; i < len; i++) { int cnt = 1, head = i, total = times[i];; if (!isVisited[i] && net[i].size() != 0) { isVisited[i] = 1; dfs(cnt, i, head, total); } if (cnt > 2 && total > 2 * k) { structGangg(head, cnt); ans.push_back(g); } } printf("%lu\n", ans.size()); sort(ans.begin(), ans.end(), cmp); for (auto it = ans.begin(); it != ans.end(); it++) { printName(it->index); printf(" %d\n", it->cnt); } return0; }
Shopping in Mars is quite a different experience. The Mars people pay by chained diamonds. Each diamond has a value (in Mars dollars M$). When making the payment, the chain can be cut at any position for only once and some of the diamonds are taken off the chain one by one. Once a diamond is off the chain, it cannot be taken back. For example, if we have a chain of 8 diamonds with values M$3, 2, 1, 5, 4, 6, 8, 7, and we must pay M$15. We may have 3 options: 1. Cut the chain between 4 and 6, and take off the diamonds from the position 1 to 5 (with values 3+2+1+5+4=15). 2. Cut before 5 or after 6, and take off the diamonds from the position 4 to 6 (with values 5+4+6=15). 3. Cut before 8, and take off the diamonds from the position 7 to 8 (with values 8+7=15). Now given the chain of diamond values and the amount that a customer has to pay, you are supposed to list all the paying options for the customer. If it is impossible to pay the exact amount, you must suggest solutions with minimum lost.
Input Specification:
Each input file contains one test case. For each case, the first line contains 2 numbers: N (<=105), the total number of diamonds on the chain, and M (<=108), the amount that the customer has to pay. Then the next line contains N positive numbers D1 … DN (Di<=103 for all i=1, …, N) which are the values of the diamonds. All the numbers in a line are separated by a space.
Output Specification:
For each test case, print “i-j” in a line for each pair of i <= j such that Di + … + Dj = M. Note that if there are more than one solution, all the solutions must be printed in increasing order of i. If there is no solution, output “i-j” for pairs of i <= j such that Di + … + Dj > M with (Di + … + Dj - M) minimized. Again all the solutions must be printed in increasing order of i. It is guaranteed that the total value of diamonds is sufficient to pay the given amount.
intfindNearM(int *sum, int l, int r, int v){ int mid = 0; while (l < r) { mid = (l + r) / 2; if (sum[mid] >= v) r = mid; else l = mid + 1; } return l; }
intmain(){ int n = 0, m = 0; scanf("%d %d", &n, &m); int *sum = newint[n + 1]; sum[0] = 0; for (int i = 1; i <= n; i++) { int t = 0; scanf("%d", &t); sum[i] = sum[i - 1] + t; }
int nearM = 100000; for (int i = 0; i < n; i++) { int j = findNearM(sum, 1, n, sum[i] + m); if (sum[j] - sum[i] - m >= 0 && sum[j] - sum[i] - m < nearM) nearM = sum[j] - sum[i] - m; }
for (int i = 0; i < n; i++) { int j = findNearM(sum, 1, n, sum[i] + m + nearM); if (sum[j] - sum[i] - m == nearM) { printf("%d-%d\n", i + 1, j); } } delete[] sum; return0; }
This time, you are supposed to help us collect the data for family-owned property. Given each person’s family members, and the estate(房产)info under his/her own name, we need to know the size of each family, and the average area and number of sets of their real estate.
Input Specification:
Each input file contains one test case. For each case, the first line gives a positive integer N (<=1000). Then N lines follow, each gives the infomation of a person who owns estate in the format: ID Father Mother k Child1 … Childk M_estate Area where ID is a unique 4-digit identification number for each person; Father and Mother are the ID’s of this person’s parents (if a parent has passed away, -1 will be given instead); k (0<=k<=5) is the number of children of this person; Childi’s are the ID’s of his/her children;M_estate is the total number of sets of the real estate under his/her name; and Area is the total area of his/her estate.
Output Specification:
For each case, first print in a line the number of families (all the people that are related directly or indirectly are considered in the same family). Then output the family info in the format: ID M AVG_sets AVG_area where ID is the smallest ID in the family; M is the total number of family members; AVG_sets is the average number of sets of their real estate; and AVG_area is the average area. The average numbers must be accurate up to 3 decimal places. The families must be given in descending order of their average areas, and in ascending order of the ID’s if there is a tie.
Eva loves to collect coins from all over the universe, including some other planets like Mars. One day she visited a universal shopping mall which could accept all kinds of coins as payments. However, there was a special requirement of the payment: for each bill, she must pay the exact amount. Since she has as many as 104 coins with her, she definitely needs your help. You are supposed to tell her, for any given amount of money, whether or not she can find some coins to pay for it.
Input Specification:
Each input file contains one test case. For each case, the first line contains 2 positive numbers: N (<=104, the total number of coins) and M(<=102, the amount of money Eva has to pay). The second line contains N face values of the coins, which are all positive numbers. All the numbers in a line are separated by a space.
Output Specification:
For each test case, print in one line the face values V1 <= V2 <= … <= Vk such that V1 + V2 + … + Vk = M. All the numbers must be separated by a space, and there must be no extra space at the end of the line. If such a solution is not unique, output the smallest sequence. If there is no solution, output “No Solution” instead. Note: sequence {A[1], A[2], …} is said to be “smaller” than sequence {B[1], B[2], …} if there exists k >= 1 such that A[i]=B[i] for all i < k, and A[k] < B[k].
boolcmp(int arg1, int arg2){ if (arg1 > arg2) return1; return0; }
intmain(){ vector<int> coins; int n = 0, m = 0; scanf("%d %d", &n, &m); for (int i = 0; i < n; i++) { int c = 0; scanf("%d", &c); if (c <= m) { coins.push_back(c); } } sort(coins.begin(), coins.end(), cmp); n = coins.size();
int *dp = newint[m + 1]; int **s = newint *[n]; for (int i = 0; i < n; i++) { s[i] = newint[m + 1]; fill(s[i], s[i] + m, 0); } fill(dp, dp + m + 1, 0); for (int i = 0; i < n; i++) { for (int j = m; j >= coins[i]; j--) { if (dp[j] <= dp[j - coins[i]] + coins[i]) { dp[j] = dp[j - coins[i]] + coins[i]; s[i][j] = 1; } } }
if (dp[m] != m) printf("No Solution"); else { int i = n - 1, j = m; vector<int> result; while (i >= 0) { if (s[i][j] == 1) { result.push_back(coins[i]); j -= coins[i]; } i--; } for (int i = 0; i < result.size(); i++) { printf("%d", result[i]); if (i != result.size() - 1) printf(" "); } }
for (int i = 0; i < n; i++) { delete[] s[i]; } delete[] s; delete[] dp; return0; }