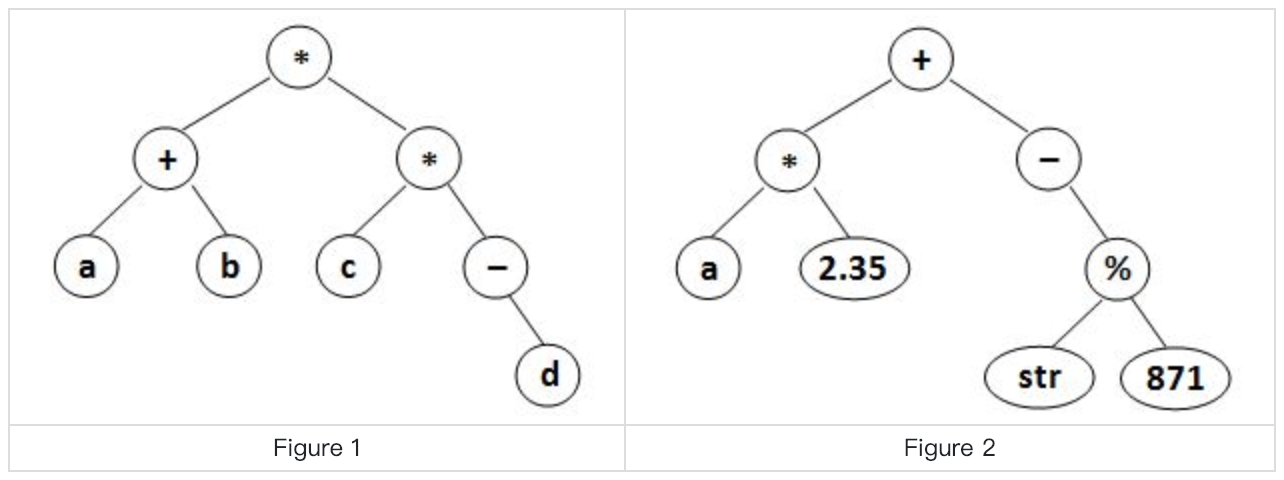
Given a syntax tree (binary), you are supposed to output the corresponding infix expression, with parentheses reflecting the precedences of the operators.
Input Specification:
Each input file contains one test case. For each case, the first line gives a positive integer N ( <= 20 ) which is the total number of nodes in the syntax tree. Then N lines follow, each gives the information of a node (the i-th line corresponds to the i-th node) in the format: data left_child right_child where data is a string of no more than 10 characters, left_child and right_child are the indices of this node’s left and right children, respectively. The nodes are indexed from 1 to N. The NULL link is represented by -1. The figures 1 and 2 correspond to the samples 1 and 2, respectively.
Output Specification:
For each case, print in a line the infix expression, with parentheses reflecting the precedences of the operators. Note that there must be no extra parentheses for the final expression, as is shown by the samples. There must be no space between any symbols.
Sample Input 1:
8 * 8 7 a -1 -1 * 4 1 + 2 5 b -1 -1 d -1 -1 - -1 6 c -1 -1
structNode { string data; int leftChildIndex, rightChildIndex; };
structNode *nodes;
introotIndex(bool *index, int n){ for (int i = 1; i <= n; i++) { if (!index[i]) { return i; } } return-1; }
voidprintTree(int rootIndex){ int left = nodes[rootIndex].leftChildIndex; if (left != -1) { if (nodes[left].leftChildIndex != -1) printf("("); printTree(nodes[rootIndex].leftChildIndex); if (nodes[left].leftChildIndex != -1) printf(")"); } cout << nodes[rootIndex].data; int right = nodes[rootIndex].rightChildIndex; if (right != -1) { if (nodes[right].rightChildIndex != -1) printf("("); printTree(nodes[rootIndex].rightChildIndex); if (nodes[right].rightChildIndex != -1) printf(")"); } }
intmain(){ int n = 0; cin >> n; nodes = newstruct Node[n + 1]; bool *index = newbool[n + 1]; for (int i = 1; i <= n; i++) { cin >> nodes[i].data >> nodes[i].leftChildIndex >> nodes[i].rightChildIndex; if (nodes[i].leftChildIndex != -1) index[nodes[i].leftChildIndex] = true; if (nodes[i].rightChildIndex != -1) index[nodes[i].rightChildIndex] = true; } int root = rootIndex(index, n); if (root == -1) { cout << "error"; } else { printTree(root); } delete[] index; delete[] nodes; return0; }
A Binary Search Tree (BST) is recursively defined as a binary tree which has the following properties:
The left subtree of a node contains only nodes with keys less than the node’s key.
The right subtree of a node contains only nodes with keys greater than or equal to the node’s key.
Both the left and right subtrees must also be binary search trees.
If we swap the left and right subtrees of every node, then the resulting tree is called the Mirror Image of a BST. Now given a sequence of integer keys, you are supposed to tell if it is the preorder traversal sequence of a BST or the mirror image of a BST.
Input Specification:
Each input file contains one test case. For each case, the first line contains a positive integer N (<=1000). Then N integer keys are given in the next line. All the numbers in a line are separated by a space.
Output Specification:
For each test case, first print in a line “YES” if the sequence is the preorder traversal sequence of a BST or the mirror image of a BST, or “NO” if not. Then if the answer is “YES”, print in the next line the postorder traversal sequence of that tree. All the numbers in a line must be separated by a space, and there must be no extra space at the end of the line.
voidgetPost(std::vector<int> &post, int s, int e, bool mirror){ if (s > e) { return; } int i = s + 1, j = e; if (!mirror) { while (i <= e && pre[s] > pre[i]) i++; while (j > s && pre[s] <= pre[j]) j--; } else { while (i <= e && pre[s] <= pre[i]) i++; while (j > s && pre[s] > pre[j]) j--; } if (i - j != 1) return; getPost(post, s + 1, j, mirror); getPost(post, i, e, mirror); post.push_back(pre[s]); }
intmain(){ int n = 0; scanf("%d", &n); pre = newint[n]; for (int i = 0; i < n; i++) { scanf("%d", &pre[i]); } std::vector<int> post; getPost(post, 0, n - 1, false); if (post.size() != n) { post.clear(); getPost(post, 0, n - 1, true); } if (post.size() == n) { printf("YES\n%d", post[0]); for (int i = 1; i < post.size(); i++) { printf(" %d", post[i]); } } else { printf("NO"); } delete[] pre; return0; }
Suppose that all the keys in a binary tree are distinct positive integers. A unique binary tree can be determined by a given pair of postorder and inorder traversal sequences. And it is a simple standard routine to print the numbers in level-order. However, if you think the problem is too simple, then you are too naive. This time you are supposed to print the numbers in “zigzagging order” – that is, starting from the root, print the numbers level-by-level, alternating between left to right and right to left. For example, for the following tree you must output: 1 11 5 8 17 12 20 15.
Input Specification:
Each input file contains one test case. For each case, the first line gives a positive integer N (<= 30), the total number of nodes in the binary tree. The second line gives the inorder sequence and the third line gives the postorder sequence. All the numbers in a line are separated by a space.
Output Specification:
For each test case, print the zigzagging sequence of the tree in a line. All the numbers in a line must be separated by exactly one space, and there must be no extra space at the end of the line.
structtree { int val, level; structtree *left, *right; };
intfindRootInInorder(int inl, int inr, int val){ for (int i = inl; i <= inr; i++) { if (in[i] == val) return i; } return-1; }
structtree *buildTree(int inl, int inr, int postRoot, struct tree *root, int level) { if (inl > inr) returnNULL; if (root == NULL) root = newstructtree(); int inRoot = findRootInInorder(inl, inr, post[postRoot]); root->val = post[postRoot]; root->level = level; root->left = buildTree(inl, inRoot - 1, postRoot - inr + inRoot - 1, root->left, level + 1); root->right = buildTree(inRoot + 1, inr, postRoot - 1, root->right, level + 1); return root; }
vector<vector<int> > getLevelOrder(struct tree *root) { vector<vector<int> > levelOrder(30); queue<struct tree *> q; q.push(root); while (!q.empty()) { structtree *t = q.front(); q.pop(); levelOrder[t->level].push_back(t->val); if (t->left != NULL) q.push(t->left); if (t->right != NULL) q.push(t->right); } return levelOrder; }
voidprintZigZag(vector<vector<int> > levelOrder){ printf("%d", levelOrder[0][0]); for (int i = 1; i < levelOrder.size(); i++) { if (i % 2 == 0) { for (int j = levelOrder[i].size() - 1; j >= 0; j--) { printf(" %d", levelOrder[i][j]); } } else { for (int j = 0; j < levelOrder[i].size(); j++) { printf(" %d", levelOrder[i][j]); } } } }
intmain(){ int n = 0; scanf("%d", &n); in.resize(n); post.resize(n); for (int i = 0; i < n; i++) { scanf("%d", &in[i]); } for (int i = 0; i < n; i++) { scanf("%d", &post[i]); }
structtree *root = buildTree(0, n - 1, n - 1, NULL, 0); vector<vector<int> > levelOrder = getLevelOrder(root); printZigZag(levelOrder); return0; }
intmain(){ int m = 0, n = 0, s = 0; cin >> m >> n >> s; vector<string> forward(m + 1); for (int i = 1; i <= m; i++) { string nickname; cin >> nickname; forward[i] = nickname; }
if (s > m) { cout << "Keep going..." << endl; } else { map<string, bool> winner; cout << forward[s] << endl; winner[forward[s]] = true; int i = s; while (i < m) { int cnt = 0; while (i < m && cnt < n) { i++; if (!winner[forward[i]]) { cnt++; } } if (n == cnt) { cout << forward[i] << endl; winner[forward[i]] = true; } } } return0; }
intmain(){ int n = 0; scanf("%d", &n); priority_queue<int, vector<int>, greater<int> > q; for (int i = 0; i < n; i++) { int temp = 0; scanf("%d", &temp); q.push(temp); }
while (q.size() > 1) { int a = q.top(); q.pop(); int b = q.top(); q.pop();
In graph theory, an Eulerian path is a path in a graph which visits every edge exactly once. Similarly, an Eulerian circuit is an Eulerian path which starts and ends on the same vertex. They were first discussed by Leonhard Euler while solving the famous Seven Bridges of Konigsberg problem in 1736. It has been proven that connected graphs with all vertices of even degree have an Eulerian circuit, and such graphs are called Eulerian. If there are exactly two vertices of odd degree, all Eulerian paths start at one of them and end at the other. A graph that has an Eulerian path but not an Eulerian circuit is called semi-Eulerian. (Cited from https://en.wikipedia.org/wiki/Eulerian_path) Given an undirected graph, you are supposed to tell if it is Eulerian, semi-Eulerian, or non-Eulerian.
Input Specification:
Each input file contains one test case. Each case starts with a line containing 2 numbers N (<= 500), and M, which are the total number of vertices, and the number of edges, respectively. Then M lines follow, each describes an edge by giving the two ends of the edge (the vertices are numbered from 1 to N).
Output Specification:
For each test case, first print in a line the degrees of the vertices in ascending order of their indices. Then in the next line print your conclusion about the graph – either “Eulerian”, “Semi-Eulerian”, or “Non-Eulerian”. Note that all the numbers in the first line must be separated by exactly 1 space, and there must be no extra space at the beginning or the end of the line.